Partitions, Partitions and Partitions.
Oct. 6, 2022Recently we have come across an issue where one of the component of our ETL pipeline hav exploded in aws cost. When we took a deeper look into it we learnt an expensive lesson on data partitions. Overall architecture of our Data ETL pipeline is as follows
In this whole Workflow majority of cost is occurred on AWS Glue and Redshift database on which our API server operates, and rightfully so. AWS Glue job converts our flat text files into parquet files in bulk every 4 hours. The Glue job is ran per table for all sites in a tenant combined, thus it fetches all unprocessed files from all the sites and processes them one time. This is due to multiple reasons
- Redshift is columnar database and deletes and updates are very expensive operation.
- It is efficient to process bulk of files in Glue rather than small files.
redshift is a columnar database. in a traditional row based database systems all the data belonged to the row is stored together thus when we wanted to update a particular row we could update the row by updating a single data page block. however in Redshift is column based and compressed in 1MB columnar block. So single row update/delete will touch multiple blocks and this problem is amplified if no of rows are large which is the case in our application. So the general consensus is to minimize update and delete operations. And our decision to process data of all sites for a single table is impacted by the infamous and dreadful isolation exception of Redshift when multiple updates are happening in single table.
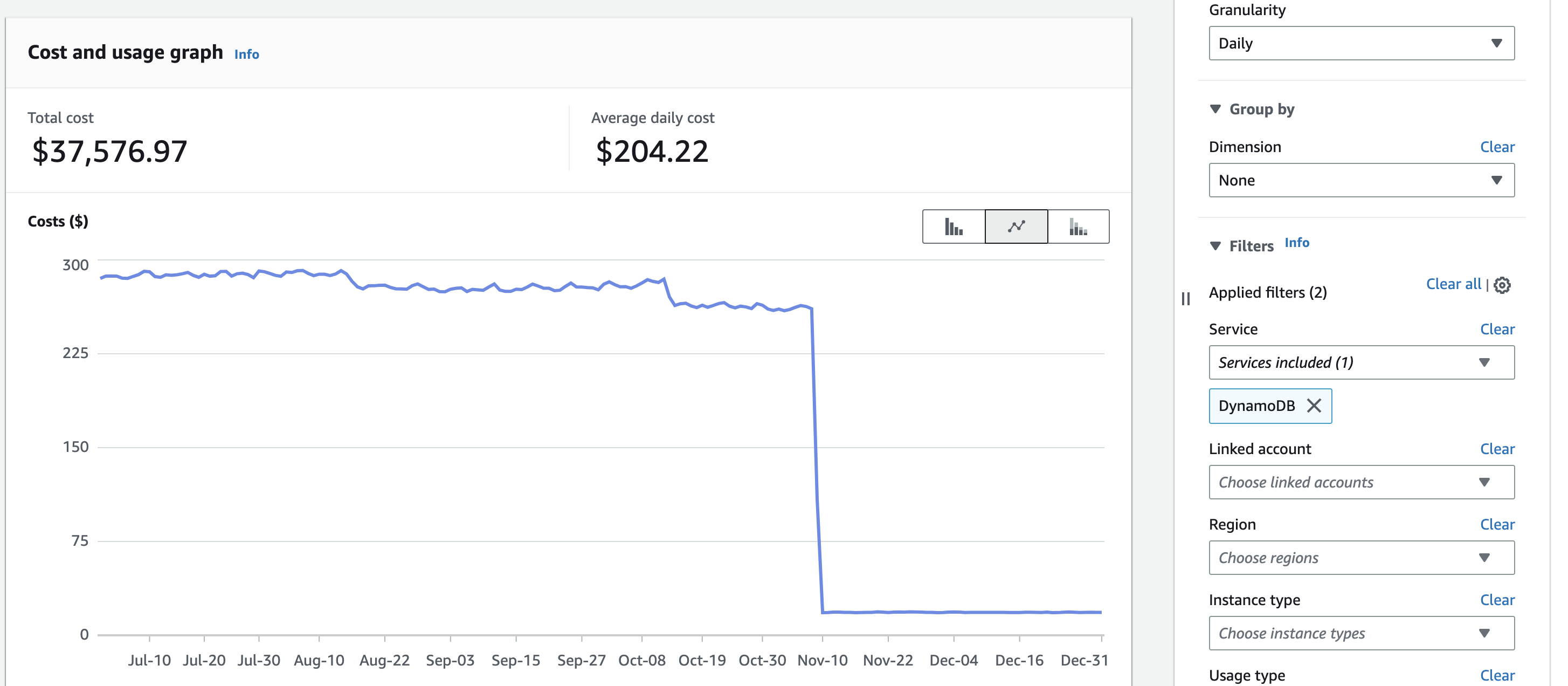
Now it has been brought to team’s notice that our dynamodb cost’s which is exclusively used to track unprocessed files are on par with our redshift database which has 100’s of Terabytes of data i instantly knew the culprit. It was full table scans, it has to be. the storage of dynamodb data is within free tier of dynamodb.
The schema of dynamodb table tracking is like this
| raw_table_name | s3_key | insert_timestamp | is_processed |
|---|---|---|---|
| table1 | tenant1/site1/table1/initial/timestamp.csv | 1970-01-01 | true |
| table1 | tenant1/site1/table1/initial/timestamp.csv | 1970-01-01 | true |
| table1 | tenant1/site1/table1/initial/timestamp.csv | 1970-01-01 | true |
| table1 | tenant1/site1/table1/initial/timestamp.csv | 1970-01-01 | true |
| table1 | tenant1/site1/table1/initial/timestamp.csv | 1970-01-01 | true |
| table1 | tenant1/site1/table1/incremental/timestamp.csv | 1970-01-01 | true |
| table1 | tenant1/site1/table1/incremental/timestamp.csv | 1970-01-02 | true |
| table1 | tenant1/site1/table1/incremental/timestamp.csv | 1970-01-03 | true |
| table1 | tenant1/site1/table1/incremental/timestamp.csv | 1970-01-04 | false |
| table1 | tenant1/site1/table1/incremental/timestamp.csv | 1970-01-05 | false |
| table1 | tenant1/site2/table1/initial/timestamp.csv | 1970-01-01 | true |
| table1 | tenant1/site2/table1/initial/timestamp.csv | 1970-01-01 | true |
| table1 | tenant1/site2/table1/initial/timestamp.csv | 1970-01-01 | true |
| table1 | tenant1/site2/table1/initial/timestamp.csv | 1970-01-01 | true |
| table1 | tenant1/site2/table1/initial/timestamp.csv | 1970-01-01 | true |
| table1 | tenant1/site2/table1/incremental/timestamp.csv | 1970-01-01 | true |
| table1 | tenant1/site2/table1/incremental/timestamp.csv | 1970-01-02 | true |
| table1 | tenant1/site2/table1/incremental/timestamp.csv | 1970-01-03 | true |
| table1 | tenant1/site2/table1/incremental/timestamp.csv | 1970-01-04 | false |
| table1 | tenant1/site2/table1/incremental/timestamp.csv | 1970-01-05 | false |
where raw_table_name is the hash_key and s3_key is range_key which together form composite_key. here lies the problem Now we get the unprocessed files of a table from all sites the query would be equivalent of
select s3_key from table_name=table1 where is_processed=false;
However this will result in reading all the records of files ingested from inception and filter out processed files. however this is resulting reading all records and thus consuming read capacity units for all records even though the result records are minute no of records. Now when we run jobs for all tables we are effectively reading full table with millions of records every time every ingestion cycle.
This is slowing down the query and thus also costing us AWS Glue time. One Obvious solution to this problem is to delete records of processed files but we are not doing this at this point in time.Also we are migrating newer process where we are in process of moving away from AWS Glue.
The solution to this problem is to increase specificity of read query to only read subset of records thus speeding up query and also reduce read capacity units consumed. The goal is take easiest path in solving this problem.
The approach we have taken to solve this problem is to create a meta table in which we have populated metadata in the table by having a lower-bound and upper-bound of timestamp which is used to search the records in dynamodb using between operator on sort index. This significantly reduced our RCu consumption by order of magnitude in glue jobs. and overall costs upto 40% per day. the metadata schema will look like this.
| raw_table_name | s3_key | max_processed_timestamp |
|---|---|---|
| table1 | tenant1/site1/table1/initial/ | 2020-08-01 |
| table1 | tenant1/site1/table2/initial/ | 2020-08-01 |
We have populated the metatable with a script. When a glue job is run the max processed timestamp will be updated from latest processed files timestamp. This however produced a challenge of making sure all sites and tables are updated as prefixes in the metatable which we solved using a migration script. This worked wonders for our Dynamodb read costs and the lesson learned is simple.
UPDATE: When the above fix is deployed into our production and cost are observed our average cost fell from $280 per day to $18 per day. Netting gain of cool $95000 per annum. Not bad for simple metatable.