Migrate! To AWS we go.
Sep. 26, 2022I was given the task of investigating and migrating apps to aws. The Objective is simple. Migrate all of Application running on Cloudfoundry to Amazon web services. Lets get started.all of our applications are plain spring boot 1.5x applications and containerizing spring boot application is easy.
Container Runtime.
First step of challenge is choose where to run our applications. If these were my personal applications i would rent out bunch of Linux VM’s either from AWS or from other simple cloud services and run them all as docker containers individually or as simple systemd services which is a solution that will not work for my enterprise for multitude of reasons.
- SSH to the production environment even with robust pem based auth is not allowed as this leads to security concerns.
- This is clunky and unnecessary when scaling is considered.
Ruling out this options we need to select a container orchestration service. ECS and EKS or run them using AWS app runner. Both are offered as a managed solution by all the major cloud vendors like AWS, Azure and GCP. Our apps have simpler requirements with no need for service to service communication as of now.Both ECS and EKS offer similar capabilities although with different nomenclature. In k8s container collection is called pods while in ECS they are called tasks and a service in ECS is called Deployment in EKS. Now to access these services we can use load balancers in ECS or App mesh service. K8s have multiple options to use a simple service or a ingress controller.
We have decided to go with ECS as our container management service as it seemed simpler and thus have lower entry barrier with opinionated approach to running containers. Want service to service containers ? use app mesh. Load balancing ? use ALB. EKS while extremely flexible has plethora of options that seemed complex for our use case.
With Container management service decided we will decide the total lifecycle of the deployment of services to the Containers
Our Application is a spring boot jar thus packaging would be pretty straight forward.
- Create a jar file and package it as Docker
- Upload Docker image to ECR or private github repo
- Create a ECR cluster and service
- Create Application Load balancer
- Set UP CI/CD pipeline and deploy through aws cli and task definition files.
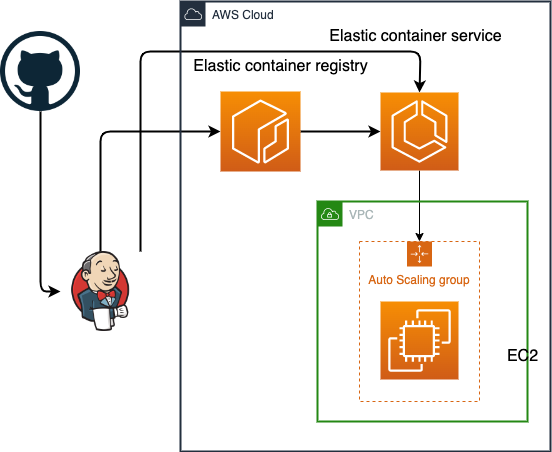
As we have decided on the container runtime services we need to figure out few more things.
- how to inject secrets and where to store them ?
- how to manage the configurations of all the containers ?
Configurations, Secrets and Auth.
Nearly all applications contain secrets. For injecting them into multiple container is a challenge. Our application is a multi-tenant application with each tenant data completely isolated. thus each tenant data might be in completely different accounts/buckets/databases. We have to make application aware of tenant information so that we can search fetch the secrets of that tenant. Injecting tenants as environmental variables into containers is the chosen approach. AWS provides env variables injection via two methods. While injecting via s3 location for bulk env variables remain viable option for lot of use cases, We chose to inject via task def files as this enables us to track them using git which will act as single source of truth.
{
"family": "application-task-definition",
"containerDefinitions": [
{
"name": "application",
"image": "dockerhub.io/applciation:1.0",
...
"environment": [
{
"name": "tenants",
"value": "b1d46aca-fef1-4e7b-959d-367c8a79d5c0,306ccc1b-5a8f-4200-a079-35c6e041d06e"
}
],
...
}
],
...
}
After injecting tenants into task definition files comes the part of fetching secrets of respective tenants. We can in theory store these secrets in a database like postgres or key value stores like mongodb or dynamodb. However we have to build interfaces to insert these secrets without database access to people configuring this. Also compliance in storing secrets is task that takes away dev time from focusing on business case. Fortunately every cloud provider provides secrets managements in built into clouds. For secrets amazon offers a service called secrets manager. which allows us to store secrets in encrypted format. this is better than storing them in a database as secrets manger lets you inject secrets into container directly as env variables in both ECS and EKS.
Secrets are stored as json file for each tenant and retrieved during runtime. This allows flexibility to use same secrets in multiple application thus avoiding duplication. We can also run a polling mechanism to fetch changes to secrets which is not possible if we are injecting them as env variables into containers.
Every service needs authorization and authentication services. Oauth with jwt tokens is what we are using right now for auth services in our workflow. all our services are oauth resource servers and doesn’t have UI. We have decided to stick with cloudfoundry uaa for our oauth needs. we are going to run docker container backed by postgres instance.
Tuning and optimizing the application resource usage.
Since we have deployed out container applications lets optimize a little. since all our applications a little to play nice with other applications running in the cluster. Traditionally when we run containers in out computer the container/application is free to use all available cpu cores ans memory in the system until OOM killer intervenes. This would not fly in case of out production environment where we need some kind of restrictions. This would also allow us to optimize resource usage of underlying VM’s
In ECS task definitions there are two locations we can specify cpu and memory in task definition. containerDefinitions section and task section. As we know a task can contain multiple containers this each container in container definition can specify individual limits. All our application contain single container per task. When a cpu and memory are specified in task definition its acts as hard boundary thus task reserves cpu and memory reserved in the host and also all the containers in the task cannot exceed this hard limit. This option is recommended for Guaranteed resources from host but setting this option has downsides as other containers cannot use this resources even when our task/application is idle. The task size is mandatory for fargate launch type as this hard boundary is required for allocation of serverless compute resources.
For our use case to optimize resource usage we don’t specify task size and specify memoryReservation and memory parameters in the containerDefinitions section. Here host will reserve memory size of memoryReservation and will allow container to use upto memory specified in container definition. thus memory is an upper bound and memoryReservation is lower-bound. memoryReservation parameter will ensure that no other process can use the memory reserved for this container.
For example if we have host with 8gb RAM/memory and have a container/task (i.e single container per task in this scenario) memoryReservation of 2gb and memory of 4gb then we can place maximum of 4 tasks in the host. 5th task will fails as no memory is available.
We have looked at the memory reservation part of the container cpu reservation works differently. when you specify cpu on wither task or container level the CPU units are reserved for your task or container. but unlike memory cpu units can be share between process when not in use.
For example if host has 2048 cpu units and we have a task with cpu reservation 1024 we can run maximum 2 tasks on the host even when when actual cpu usage is less than available on host. cpu reservation only matters when cpu resources are in contention. then host will restrict tasks or containers to their respective reservations. if cpu resources are not in contention actual usage many be higher than specified.
see below links for excellent overview of this topic.
- How Amazon ECS manages CPU and memory resources
- What do I need to know about CPU allocation in Amazon ECS?
- Task definition parameters Reference
when all this work is done and your organization decide to use fargate over ec2 due to management and security concerns you throw all the work done in dustbin and pay 2-3x for resources and move on.
Autoscaling
Autoscaling on Fargate is very simple and straight forward as the compute resources are already allocated on pay as you go basis thus scaling application in fargate meaning simply spawning more tasks rather than instantiating more ec2 instances. The trigger however is disappointingly based on a choice between single alarm metric. We have to choose between avg requests per task or average cpu utilization or avg memory utilization. so we have to determine the scaling behavior based on the individual applications behavior. if your application’s performance or throughput is limited by cpu or memory or requests. in our case its limited by memory in most of applications. thus we set an alarm on avg memory consumed by tasks. we can write custom metric that takes cloudwatch logs as input to consider cpu,memory and request and come up with some metric that can be used for alarm but for now this metric is good enough.